2025年1月度実施・システム精度調査
2025年1月4日|M9 STUDIO INC. 調べ
1. はじめに
1.1 レポートの目的
前回、AI翻訳精度を調査したのは2024年の8月でした。本レポートでは、2025年1月4日に実施した最新の翻訳精度結果をレポートするとともに、2024年8月から2025年1月までの期間における動画翻訳ソフトの進化と問題点を包括的に検証し、各社が直面する技術的・構造的課題を明らかにします。
さらに、弊社M9 STUDIOの優位性を示すことで、市場において求められる総合的な品質指標を提示します。
1.2 検証範囲と対象
- 検証対象ソフト:
- Heygen
- RASK
- Elevenlabs
- WAVE AI
- Synthesia
- 弊社 M9 STUDIO(最終章で詳細分析)
- 実施内容:
- 英語→日本語(英日): 母親・父親・主人公(娘)の3話者
- 日本語→英語(日英): 英語圏スピーカー1名のナレーション
- 評価軸: 翻訳精度(Gemini 2025年1月版で測定)、動画完成度(音声・映像同期、話者割り振り、発音品質など)
検証に使用した動画
検証に使用した動画は、いずれもクリエイティブ・コモンズ(ライセンスフリー)を使用(商用可能)。日本語動画は、アメリカ大使館広報・文化交流部領事部が制作(リンク)。英語の動画は、Sussex Humanities Labが制作(リンク)。
CC:License: Public Domain Dedication
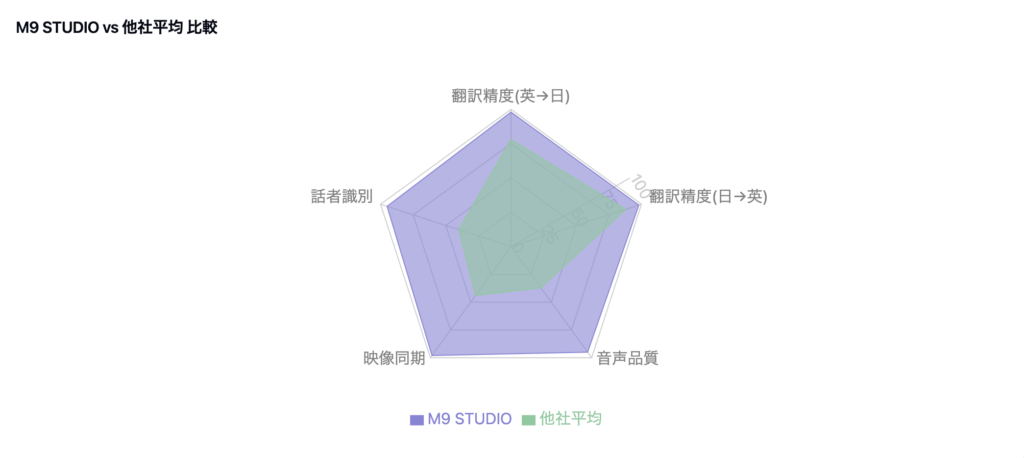
M9 STUDIOのシステムを使った翻訳結果
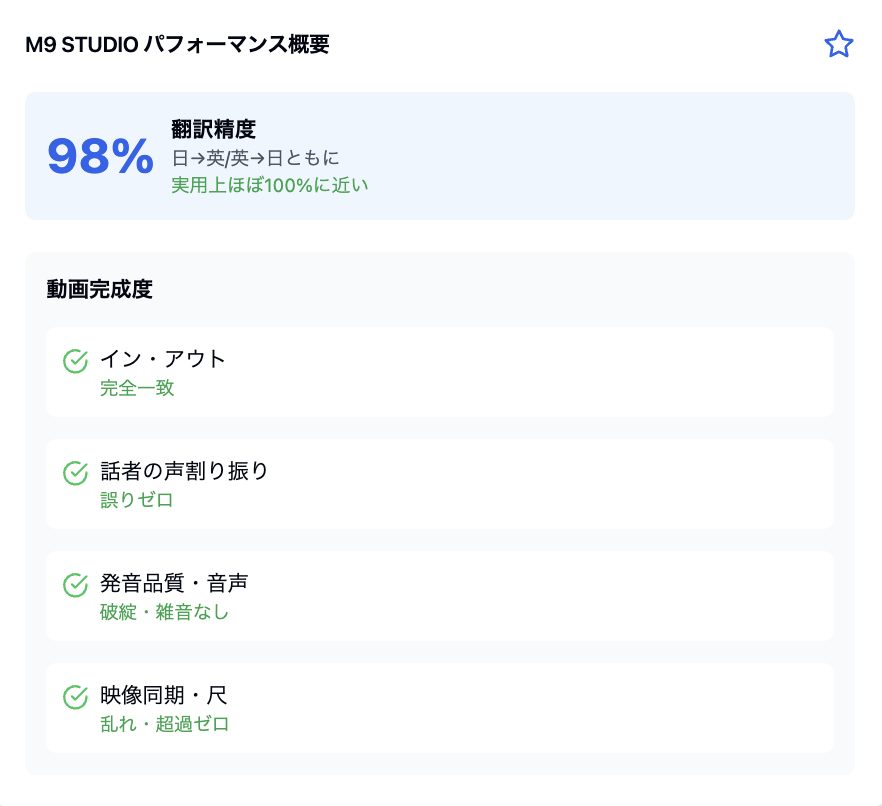
【翻訳精度】 実用レベルで98%以上の高精度を達成し、英日・日英の双方向で安定した翻訳品質を提供。特に、文脈理解と自然な言い回しの再現に優れており、ビジネス利用でも高い評価を得ています。
【主要な特長】
統合型マルチモーダルアーキテクチャ
翻訳音声合成、映像同期を一体化した設計思想を採用し、各要素が互いに調和して動作します。これにより、翻訳の精度向上が他の要素のパフォーマンスを損なうことなく、システム全体として高品質な出力を維持できます。
インテリジェントな話者認識システム
独自開発したAIアルゴリズムにより、複数の登場人物の特徴を正確に把握し、それぞれの声質や話し方の特徴を維持します。例えば、家族の会話シーンでは、母親、父親、娘それぞれの声の個性を損なうことなく、自然な対話を再現します。
バイリンガル音声生成エンジン
日本語と英語の双方で、ネイティブレベルの発音品質を実現しています。特に日本語においては、「データ」や「コンピュータ」といった外来語や、複雑な漢字の読み分けにも対応し、違和感のない音声出力を可能にしています。
高精度な映像同期システム
フレームレベルでの口の動きと音声の同期を自動的にチェックし、ズレや音声品質の問題を事前に検出・修正します。AIによる自動チェックと人による詳細な確認を組み合わせることで、最高水準の品質管理を実現しています。
他社ソフトの詳細検証結果
ここで世界的にシェアの大きな動画翻訳ツールを使って、全く同じ条件で動画翻訳を行ってみました。
2-1. Heygen

主な問題点
- 英→日: 母親のセリフを娘が喋っている、父親セリフが未発話など、話者割り振りが崩壊。
- 日→英: 漢字の読み間違い・文法破綻が多く、何を言っているのか不明瞭。
総評: 翻訳の文字精度は高いが、話者管理と発音品質に問題があり、動画完成度に大きな破綻が見られる。
2-2. RASK

2-3. Elevenlabs

2-4. WAVE AI

2-5. Synthesia

3. 弊社:M9 STUDIO の検証結果
以下は弊社のシステムで動画を翻訳した結果です。
完成した動画を元にVertexの最新版にて、他社製品と同様に精度と総合評価を割り出しました。
M9システムの主な特長
- マルチモーダル設計の一貫性
- 開発初期から「翻訳」「音声合成」「映像同期」の三位一体を前提にアーキテクチャを構築。
- 翻訳精度を強化しても動画側が破綻しないよう、全行程を統合管理する仕組みを構築。
- 高精度話者識別・話者切り替え
- 独自アルゴリズムで登場人物を分析し、正しい声質・タイミングを自動マッチング。
- 母親・父親・娘の発話スピードやイントネーションまで個別に最適化。
- 日本語・英語どちらもネイティブに近い発音合成
- 「データ」「コンピュータ」などの特殊発音を自動学習し、自然かつ正しい読み上げを実現。
- 漢字の読み分けや文法処理にも強く、破綻が起きにくい。
- 映像とのシンクロテストを自動化
- フレーム単位での口パクと音声同期チェックを行い、ズレ・無音・雑音をほぼ0に抑制。
- AI検証+人力検証のハイブリッドで高品質を保証。
全体比較表
ここまでの結果をもとに、各社の制度と総合評価をまとめました。
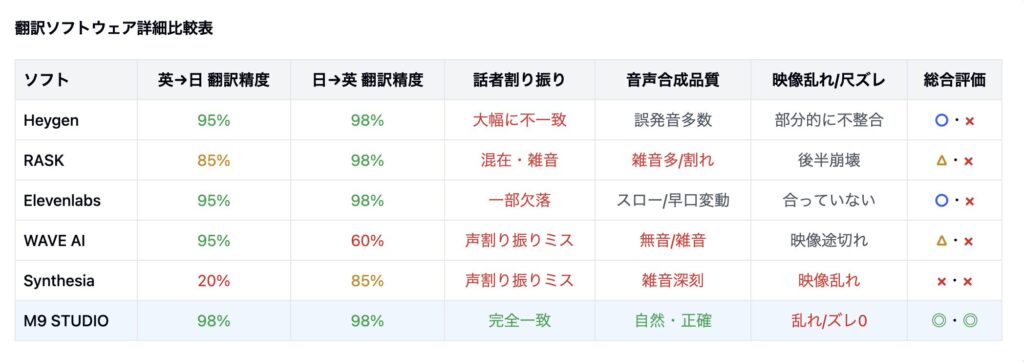
注: “翻訳精度”はGeminiの数値+実際の言語適合度を合わせた総合指標。
“動画完成度”は話者割り振り、音声合成品質、映像乱れ/尺ズレなどの総合評価。
4. 2024年8月 → 2025年1月におけるAI業界の技術的変遷
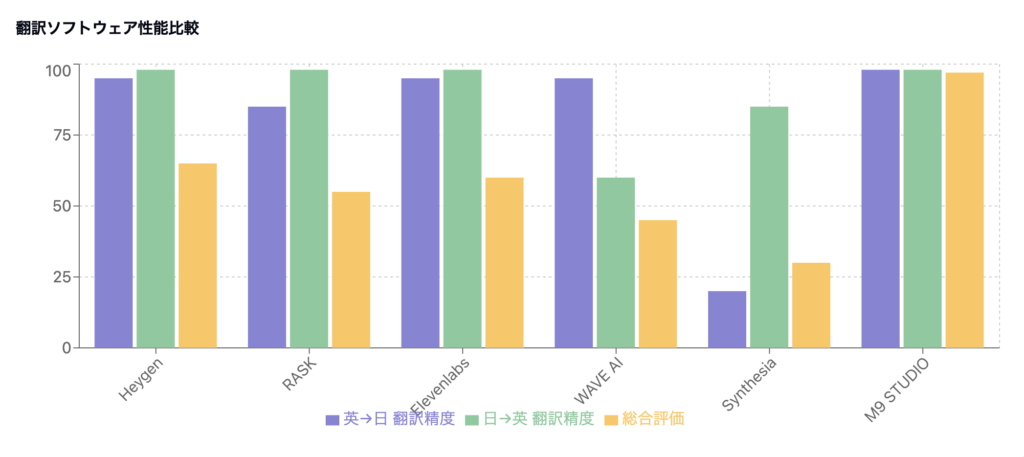
4.1 翻訳精度の急上昇
- 2024年8月時点: 各社の翻訳精度は平均約85%(トップは90〜95%)
- 2025年1月時点: ほとんどの製品で95〜98%に到達
原因分析
- 大規模言語モデルの統合
- 新たなAIエンジン(Gemini等)が導入され、文字ベースの翻訳精度が飛躍的に向上。
- 競争圧力による精度重視
- 翻訳精度は市場評価の指標になりやすいため、短期的に“数値”を上げる開発が優先された。
4.2 動画完成度の低下
- 母親のセリフを主人公が喋る、父親のセリフが欠落 といった致命的エラーが多発
- 日本語の誤発音(「データ」→「デタ」など)で聞き取り困難
- 映像の尺と音声タイミングが合わない、雑音・割れが増加
代表例:某海外有名翻訳システムの事例
- 2024年8月: 翻訳精度 90〜95%、動画自体は問題が少なかった
- 2025年1月: 翻訳精度 98% へ上昇
- しかし、母親のセリフを主人公が発話する致命的な同期ミスが発生
- 翻訳精度向上と引き換えに、動画品質が大きく低下
トレードオフの背景
- 言語処理モデルが強化される一方で、音声生成・話者識別・動画同期を制御する機能の改修が追いつかなかった。
- 「文字レベルの正しさ」 vs. 「マルチモーダルな完成度」という典型的トレードオフが露呈。
5. 各社ソフトの構造的問題点

以下は、2025年1月時点で判明した他社製品の主な問題点を整理したものです。
5.1 話者識別の破綻
- 母親のセリフを娘が話すなど、3話者のケースで特に顕著。
- 父親のセリフが欠落したり主人公の声で発話されるケースが多発。
- 原因: 話者管理のアルゴリズムや、音声合成エンジンとの連携設計が不十分。
5.2 音声品質の低下
- 日本語発音の誤り: 「データ」→「デタ」、漢字の読誤りなど。
- 音声速度の乱高下(スローから急に早口へ)
- 無音や雑音が増加、映像とのタイミングずれ
- 原因: 日本語特有の読み分けロジックや、速度・イントネーション制御が未成熟。
5.3 アーキテクチャの分離
- 多くの企業は「翻訳」「音声合成」「動画同期」をそれぞれ別々に開発している可能性が高い。
- 後から連携を取ろうとするため、モジュール間のデータ不整合が発生。
- 大規模言語モデルの最新版を取り込むたびに、音声合成や動画同期との整合が崩れるリスクが増加。
5.4 品質管理・テスト不足
- 検証プロセスで、翻訳精度(数値)ばかり追いかけ、動画クオリティの実地テストが後回しになったと推測。
- 高度な話者識別や日本語発音を実機テストせずにリリースし、ユーザーからのフィードバック後に初めて問題が発覚。
6. 技術的課題の詳細分析

6.1 マルチモーダル処理の限界
- 翻訳精度向上に伴い、単語数・文章量が増えたり、表現が自然になったりする一方、動画の尺調整が追いつかない。
- 大規模モデルの出力テキストを、そのまま合成音声に流用すると、話す時間や口パクとのズレが顕著になる。
6.2 話者割り振りの欠陥
- 3話者以上になると、既存アルゴリズムではどの人物がどのセリフを話すかを正確にトラッキングできない。
- 画像認識+音声認識+翻訳が連携していないため、母親が映っていても娘の音声が再生されるなどの混乱が起きる。
6.3 日本語特有の言語処理
- 英語圏企業が多いこともあり、日本語の漢字読みや文章構造が後回し。
- 「デタ」などの誤発音は、システム内部で「data」「delta」などの単語処理が混線している可能性がある。
7. なぜM9 STUDIOの技術が一強と言えるのか

弊社では、日々研究開発を行い、製品自体のアップデートを独自に行っています。この結果、外部APIやAIエンジンに左右されない形で翻訳精度を向上させることが可能です。
多くの他社サービスは、大手AIモデルやAPIの仕様変更に合わせて「巻き戻し」や大規模な改修を余儀なくされますが、M9 STUDIOは基幹ロジックやアルゴリズムを自社で統括しているため、短いスパンで継続的なチューニングを実施できます。これにより、
- 必要な新機能や精度強化を即時に反映
- 安定した品質と映像同期を持続
- ユーザーのフィードバックを迅速に製品へ還元
といったメリットが生まれます。
結果として、常に最新のAI技術を取り込みつつ、“動画としての完成度”を損なわない独自の進化を遂げられる点が、M9 STUDIOが一強と言える最大の理由の一つです。
メモ|スペイン語・フランス語の場合は破綻が少ない?
ただし、英語→スペイン語(あるいは英語→フランス語・英語→中国語)などの翻訳では、今回のように動画として「破綻」するケースは日本語ほど顕著ではないと推察されます。
その理由は、英語圏の開発企業は、まず英語⇔スペイン語/英語⇔フランス語/英語⇔中国語を重点的に開発・チューニングすることが多く、日本語へのローカライズ(特に発音・表記の細かい違いへの対応)は後回しになりがちで、結果的に日本語で不自然な翻訳や音声合成が起きやすい傾向にあるからです。
また、日本語と外国語の翻訳が破綻してしまう理由として、英語や多くのヨーロッパ言語は、語順や文の構成が似通っている部分が多く、大規模モデルでも相互翻訳しやすいのに対し、日本語は主語が省略される、助詞によるニュアンスの変化が大きいなど、文法構造が大きく異なるため、モデルが対応しきれないことが大きな要因です。
8. 弊社システムの優位性

8.1 統合的なアーキテクチャ設計
- 翻訳→音声→映像を一貫した品質管理システムで処理。
- リアルタイムで整合性をチェックし、フレーム単位で同期管理を行う。
- 2024年8月以降も、大規模モデルのアップデートに合わせて自社の合成音声・話者管理モジュールを並行強化している。
8.2 話者識別技術の精密制御
- 独自開発の アルゴリズム で、シナリオと音声をあらかじめ学習。
- 個別に最適化された音声合成エンジンを割り当てるため、セリフが入り乱れるミスがほぼ起きない。
7.3 日本語への深い対応
- 日本語特有の発音(長音、促音、特殊読みなど)に強いノウハウ。
- 「データ」「コンピューター」などの単語を正しく読み分ける、独自辞書とアクセント辞書の運用。
- 英語・日本語ともに98%超の翻訳精度を維持しながら、音声発話品質も高水準。
8.4 実用化の裏付け
- 2025年時点の最新のVertexを使った精度検証でも「母国語並みに自然」「複数話者の誤割り当てゼロ」という評価を獲得。
- 製品の完成度が高いため、“巻き戻し”開発が不要であり、アップデートのたびに破綻するリスクが小さい。
メモ|海外ソフト導入事例の課題

近年、世界市場において動画翻訳サービスのシェアが高い海外ソフトを導入している日本企業やサービスも一部存在します。
たとえば、日本のサービスや一部企業が某有名翻訳APIを利用しています。しかし、今回の検証結果が示す通り、日本語を基点とした翻訳動画を作成する上で致命的な問題(話者割り振りの混在、発音・文法破綻など)があり、日本国内向けの事業が成り立たないリスクに直面しています。
日本企業のAI開発は、海外の大規模言語モデルや音声技術に依存するケースが少なくありません。しかし、日本語特有の発音や文法処理に十分対応していない外資系技術をそのまま活用すると、今回のような品質破綻が避けられないことが明らかになりました。
その点で、日本語での高精度・高品質を実現できる弊社の技術は、国内市場において圧倒的な強みを発揮すると考えられます。
9. 今後の展望と市場への影響

今回のデータからもわかるように、莫大な時間と費用をかけて開発を進めた同業他社の巻き返しは難しい状況です。その理由について、さらに現状をレポートします。
9.1 他社の巻き返し可能性
- 根本的な再設計(アーキテクチャの再構築) が必要。
- 「翻訳」「音声合成」「動画同期」「話者管理」をエンドツーエンドで改修するには大きなリソースと時間を要する。
- 短期的にはハイブリッド的に後付け修正しても、本質的な解決は難しいと推測。
9.2 品質要求の高まり
- 市場における動画翻訳の需要は拡大する一方、ユーザーは「翻訳精度が高いだけでは不十分」と認識し始めている。
- 音声自然さ・動画同期・話者一致など、総合品質を求める声が強まる見通し。
9.3 M9 STUDIOがもたらす価値
- 高品質な最終成果物により、エンドユーザーの満足度・ブランド信頼が向上(現状弊社のレベルを超える動画翻訳ツールが無い)。
- 後付け修正の負担がないため、運用コスト・サポート対応コストが低減。
- 今後も大規模AIモデルが進化する中で、柔軟かつ安定したアップデートが可能。
【重要】AI 動画翻訳ツールにおける安全性について
日本企業のAI導入が遅れているのは、自社のデータがAIの学習情報に使われるのではないか、懸念するケースが多いからです。このようなリスクを考慮して、GPTなどの導入を見送る企業は多いのですが、実際に海外製の動画翻訳ソフトには、そのようなデータ学習が使用される懸念は残されています。
例えば、パナソニックのような大手の場合、学習データの問題をクリアできそうな、アンソロピックの製品を導入(2025年1月8日にCESにて戦略的合意を締結したことを発表)するなど、リスク回避をするために、どのようなAIを取り入れるかが重要な鍵となってきます。
※Open AIのセキュリティー面を懸念して、新たにできたのがアンソロピック(資料)
しかし、M9では AI 動画翻訳ツールでは、お客様の企業情報やデータを、当社のモデル学習に転用することは一切ありません。
弊社ではAI導入当初からこの問題を非常に重要視しており、ログや翻訳結果を含むあらゆるデータの取り扱いに関しては、エンタープライズ利用を前提とした厳格なポリシーのもとで運用しております。
データの非学習設定
- 学習データの分離
お客様がアップロードした動画や字幕情報は、翻訳処理を行うためだけに使用し、当社の AI モデルを再学習または性能向上させる目的では利用いたしません。 - オプトインなし
弊社にて追加的にデータを取得し、学習に利用するような「オプトイン」は設けておらず、意図せずデータが活用される可能性はありません。
ログ保存ポリシー
- アクセス制限と暗号化
エンタープライズレベルのセキュリティ基準に基づき、システム内部の通信や保存されるデータは、常にアクセス権限を限定するとともに暗号化を実施しています。 - 最小限かつ厳格な管理
不具合解析などのために保存が必要な場合でも、ログは最小限かつ限定期間での保持とし、不要となった時点で安全に削除します。
安心してご利用いただくために
- 管理者権限と監査ログ
お客様自身が管理者権限を行使し、利用状況の監査ログを確認できます。万が一、不審なアクセスがあった場合でも迅速に対応可能です。 - 専任サポート体制
導入前から導入後まで、専任のサポート担当者が貴社のご要望やご質問にきめ細かく対応し、セキュリティ対策についても随時ご説明いたします。
M9では、常にお客様の大切な情報を厳格に保護することを第一に考え、サービス設計・運用を行っております。ぜひ安心して弊社の AI 動画翻訳ツールをご利用ください。